Voice Settings
Various Dissonance audio settings can be tweaked through the VoiceSettings asset. This asset can be quickly accessed through Window > Dissonance > Quality Settings.
Warning
The default settings are usually the best option. Don't change these options without understanding exactly what the trade-off is.
Persistence⚓︎
All of these settings can be accessed at runtime from a script through Dissonance.Config.VoiceSettings.Instance. Any settings which are changed by script are automatically saved into PlayerPrefs and override the default settings (stored in the asset). This means you can configure these settings in your menus and they will persist when your application is closed and re-opened.
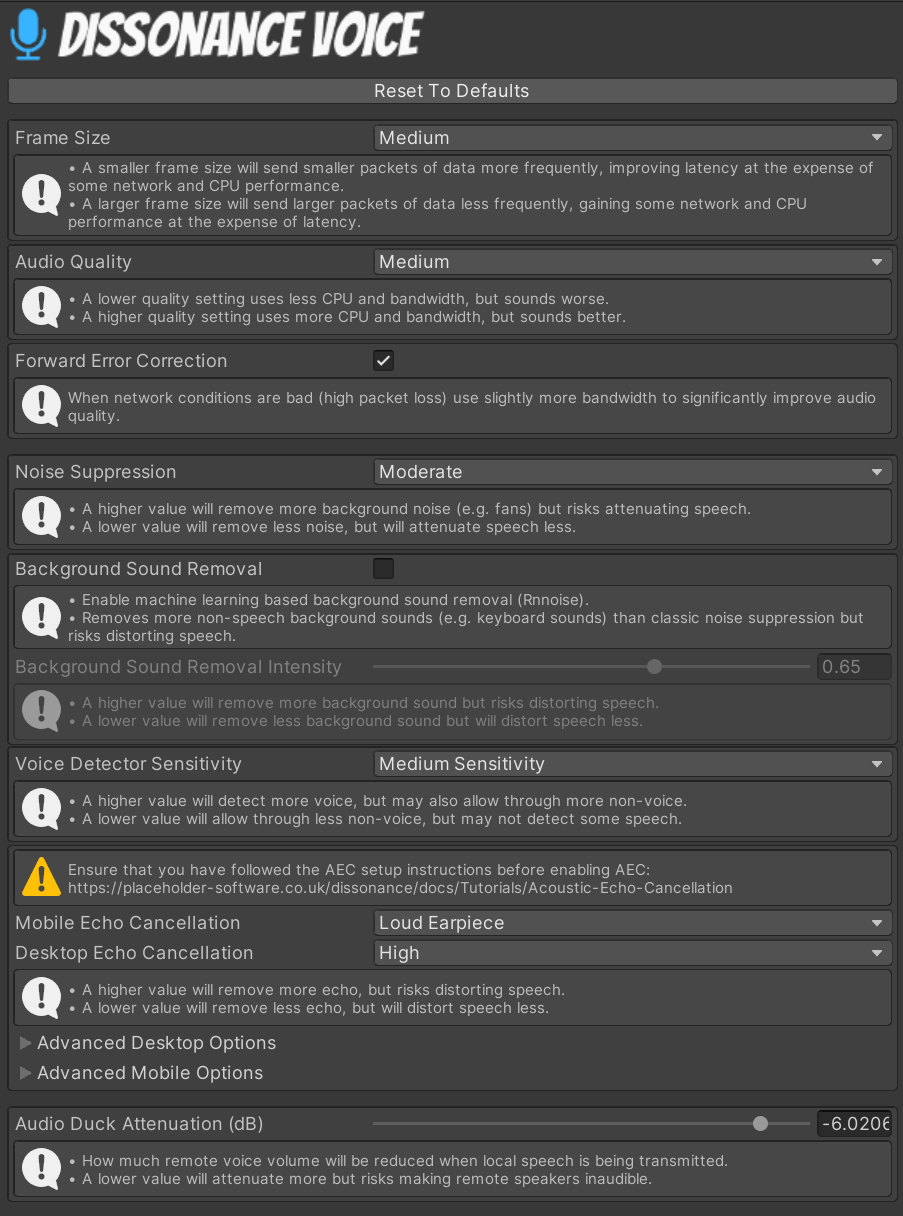
Frame Size⚓︎
Controls how much audio is packed into a single network packet. Smaller frames reduce recording latency but send more packets over the network per second, which consumes more network data and slightly more CPU power.
Warning
The smallest option (Tiny) is not suitable for use over the internet or over a wireless network. This option should only be used in very special cases where all clients will be connected to the same wired local area network.
The exact frame size at each setting is:
- Tiny: 10ms (100 packets/s)
- Small: 20ms (50 packets/s)
- Medium: 40ms (25 packets/s)
- Large: 60ms (16.6 packets/second)
Audio Quality⚓︎
Controls how many bits-per-second (on average) the audio codec will use to encode audio. Higher bitrates sound better but use more network data and slightly more CPU power.
The data rate used by each quality setting is:
- Low: 1.25 KB/s
- Medium: 2.125 KB/s
- High: 3 KB/s
Forward Error Correction⚓︎
Controls if the codec is using Forward Error Correction which improves audio quality when packets are lost. When network conditions are good this makes no difference to network data used. When network conditions are bad this slightly increases the total data used (by about 10%) and massively improves audio quality (it can almost completely mask ~5% packet loss).
Warning
It is very highly recommended to keep FEC enabled. It is a huge quality increase for a very small increase in network data usage.
Noise Suppression⚓︎
Controls how much the audio pre-processor removes noise from the signal. Higher values will remove more noise but may also make speech quieter.
Info
Sounds such as people talking in the background are not noise and will not be removed by the noise suppressor. This system removes non-voice sounds such as fans hum, keyboard clatter, or fuzz from a poor quality microphone.
Background Sound Removal⚓︎
Enables RNNoise, an ML based background sound removal system. When there is a lot of background sound (e.g. people talking, dogs barking, keyboard clatter, fan noise, loud breathing) this system will remove it, but will distort speech much more than the basic Noise Suppression system. Dissonance can run both noise removal systems at once, which reduces the amount of distortion present even in very noisy environments.
The intensity slider limits the amount of background sound that can be removed and also limits the maximum amount of distortion even in the worst case. Set it higher to cancel more noise.
It is recommended to enable this system if you are building an application where there is likely to be a lot of environmental noise (e.g. a mobile app, where the user is expected to be on-the-move while talking) or an intense VR game (where the user may be breathing heavily while talking).
Voice Detector Sensitivity⚓︎
The voice detector detects speech and activates Voice Broadcast Trigger components configured with Activation Mode: Voice Activation. This settings controls a tradeoff between accuracy (not activating when no one is speaking) and sensitivity (always activating when someone is speaking).
A low sensitivity voice detector will not activate when there is non-speech audio (e.g. keyboard clatter), but it sometimes may not activate when there is speech (e.g. quiet speech).
A high sensitivity voice detector will activate when there is speech, but it may also activate when there is non-speech audio.
Echo Cancellation⚓︎
Info
Acoustic Echo Cancellation requires some extra setup before it can be used. See this tutorial.
Controls how much echo (feedback) the acoustic cancellation system attempts to remove from recorded audio. Higher values will remove more echo but may also severely distort recorded speech.
Dissonance includes two completely different AEC algorithms which are used on Mobile and Desktop platforms. For Mobile Echo Cancellation the configuration value should approximately match the setup of the platform it is used on.
Audio Duck Attenuation⚓︎
Controls how much received Dissonance audio will be attenuated by when any VoiceBroadcastTrigger is activated (i.e. speech is being transmitted). This can help prevent feedback of recorded audio into the microphone. The AEC system is not perfect - even if you have AEC setup and working it is still worth using audio ducking.
The default value configured in Dissonance is a very mild (almost imperceptible) level of audio ducking. Much smaller values can reasonably be used, particularly on mobile platforms or VR headsets where feedback (due to speakers and microphones in close proximity) is a much more common problem.